Deep Neural Networks for YouTube Recommendations这篇文章是Youtube关于推荐系统在Deep Learning上的尝试,发表在RecSys-2016会议上。这篇文章发表之后备受关注,主要原因是,一方面它是来自Google的生产环境实践,另一方面它和目前最火的深度学习相结合,是深度学习在推荐系统中的新应用。
接下来主要介绍这篇论文的核心想法以及模型设计,最后总结我对这篇文章的一点思考。
1. 介绍
为了帮助数十亿用户从不断增长的海量视频中找到个性化的内容,Youtube的推荐系统面临着如下挑战:(1)规模大;(2)更新快;(3)噪音。
2. 系统概览
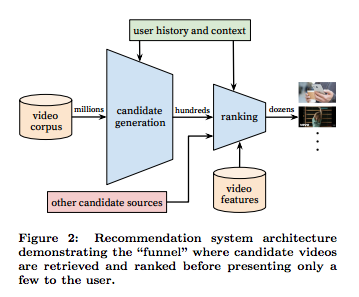
这是一个经典的信息检索两阶段系统组成:候选集生成(Candidate generation)和排序(Ranking)。候选集生成网络通过协同过滤(collaborative filtering)提供比较宽泛的个性化内容,用户之间的相似性用一些粗糙的特征表示,如观看视频的ID,查询文本以及人口统计特征等,将几百万的视频缩减到几百个。然后,选择一个合适的目标函数,用丰富的描述视频和用户的特征集合,对每个视频赋一个分值,然后根据分值排序,把最高分值的视频呈现给用户。整体流程为:视频库 -> 生成候选视频集 -> 视频排序 -> 推送推荐。
3. 候选集生成(Candidate generation)
在生成候选集的过程中,大量的YouTube视频根据用户的相关性被精选到几百个视频。先前的推荐系统在候选集生成时一般采用矩阵分解(matrix factorization)的方法,使用rank loss训练,这篇论文使用用户先前的观看历史在浅层神经网络模拟矩阵分解的行为。从这个角度来看,这种方法可以看称一种非线性分解技术的更一般形式。
3.1 推荐作为分类
将推荐看成一个超大的多分类预测问题,那么,目标就变为准确分类在t时刻观看特定的视频,这些视频来自视频库V的几百万的视频i(类别),视频库V是基于用户U和上下文C。
\[ P(w_t=i|U,C) = \frac{e^{v_i u}} {\sum_{j \in V} e^{v_j u}} \]
这是一个简单的softmax计算,比值视频i的分值和其他使用分值之和。
为了训练有效地训练几百万类别的模型,采用了candidate sampling技术。在实际的系统中,几千个负样本被采集,比传统的softmax能够加速100多倍。在生产环境下,需要计算最有可能的N个类别(视频)推送给用户,softmax输出的可能性不能用来校正,模型采用kNN搜索,kNN的选择不会改变A/B test的结果。
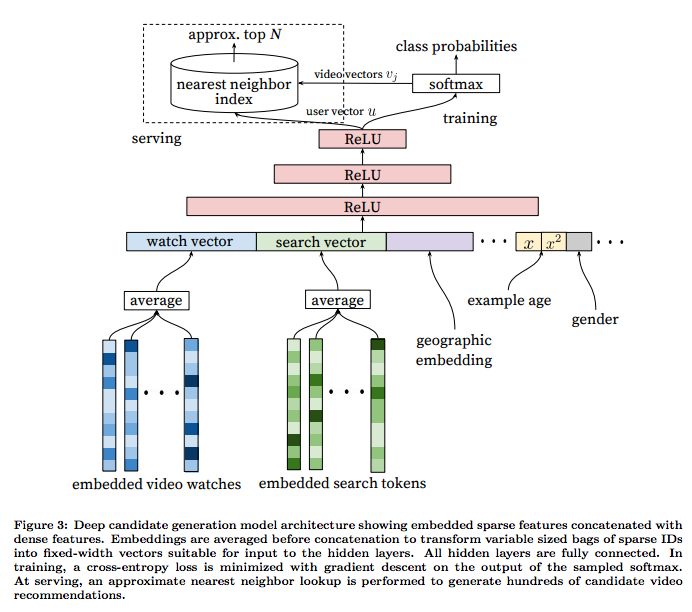
3.2 模型架构
受连续词袋模型(CBOW)的启发,模型从每个视频固定的视频库中学到高维的嵌入向量,以及额外的非视频特征,如性别、年龄等。在CBOW中,我们利用上下文去预测目标词,这里也与之类似,我们利用用户的观看历史去预测目标视频。一旦训练完嵌入向量embeddings,就可以用历史观看视频的加权平均的嵌入形式表示用户的观看历史。也可用同样的方法嵌入用户的搜索历史,将搜索分割为unigram和bigram的token,并得到token的嵌入形式。利用最近50次的观看历史和最近50次的搜索历史将视频和搜索token嵌入到长度256位的向量中。
3.3 异构信号
深度神经网络作为矩阵分解更一般的形式,其中一个关键的优势是可以把任意连续特征和类别特征加入到模型中。特征主要有:历史搜索、人口统计学信息、上下文信息、视频上传时间(example age)等。
3.4 标签和上下文选择
- 使用更广的数据:引入搜索等场景的数据;
- 为每个用户生成固定数量的样本,避免损失loss被活跃用户控制;
- 去掉序列信息,对观看历史和搜索历史的嵌入向量进行加权平均;
- 不对称的预览模式(asymmetric co-watch),(a)hled-out方式,利用上下文信息预估中间的一个视频;(b)predicting next watch方式,利用上文信息预估下一次浏览的视频;实际应用效果中,predicting next watch方式在线上A/B test中表现更佳。
3.5 不同网络深度和特征的实验
所有视频和搜索token都嵌入到256维的向量中,最开始输入层直接全连接到256维的softmax层,依次增加网络深度(512 –> 1024 –> 2048)。 网络层次结构如下:
- Depth 0:线性层,把拼接层简单转换为匹配的softmax,维度为256;
- Depth 1:256 ReLU;
- Depth 2:512ReLU -> 256 ReLU;
- Depth 3:1024ReLU -> 512ReLU -> 256 ReLU;
- Depth 4:2048ReLU -> 1024ReLU -> 512ReLU -> 256 ReLU;
4. 排序(Ranking)
当对推荐的视频进行排序时,可以非常灵活地输入更多的描述用户和视频关联的特征,因为此时只对其中非常少的(100多部)候选视频排序,这些视频来自第一个阶段——候选集生成。然后,采用与第一个阶段类似的DNN结构,使用LR对每部视频赋予一个独立的分值,对分值进行排序,并将结果返回给用户。
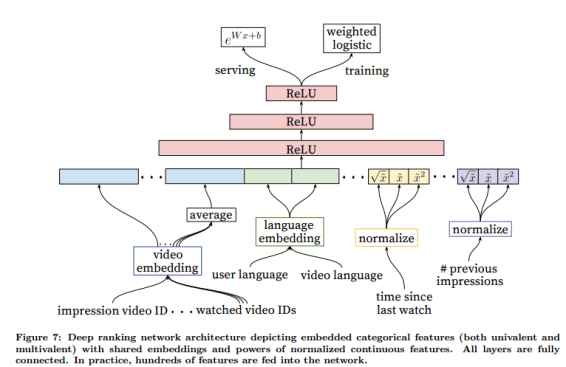
4.1 特征表示
特征分为连续特征(continuous feature)、离散特征(categorical feature)以及顺序特征(oridinal feature),离散特征有二值、或者几百万种可能取值等。排序模型使用到了几百个特征,但是在工程上还是要付出很多。尽管深度学习的愿景是减少手动挑选特征的工作量,但是原始数据是不能直接输入到前馈神经网络,仍然需要大量的工程对原始的用户数据和视频数据转换为有用的特征。最大的挑战是表示用户行为的时序数据(temporal sequence of user actions),以及这些行为和视频印象分值的关系。
- 嵌入离散特征 使用嵌入技术(embedding)把稀疏离散特征映射成稠密的适合神经网络的表示,在巨大id空间中,并非为所有的id都进行嵌入,只提取频繁点击的tok-N个视频的id,其余置为0。同时,同维度不同特征在相同的id空间共享相同的嵌入向量,大大加速训练。
- 归一化连续特征 神经网络对输入的分布和尺度比较敏感,通过归一化技术是输入映射到[0,1]区间,同时对输入变量进行次幂(如\(x^2, sqrt(x)\))转换操作,这样通过对变量施加非线性函数,使得网络更有变现力。
4.2 建模期望观看时长(watch time)
排序模型(ranking model)的整体目标是预测用户的期望观看时长,用户在视频上的观看时长被标记为正样本。为了准确预测用户的期望观看时长,采用加权的LR模型技术。
4.3 不同隐含层的实验
对于候选集生成模型和排序模型,都增加了隐层的宽度和深度改进结果。尽管排序模型是一个经典的机器学习分类问题,但是深度学习方法在预测期望观看时长时仍然比线性方法和基于树的方法要好。
4.4 其他要点
- 增加隐层的深度和宽度是有益的,但是需要在CPU时间上做trade-off。
- 线上评价指标(A/B testing)和离线评价指标(如准确率、召回率、排序损失ranking loss等)会出现不一样的结果;
- 在YouTube,隐式的反馈(如点赞,喜欢等)是稀疏的,并且并非是正样本的指标。相反地,应该把视频是否看完(watch time)作为正样本的判断。同时,点击视频也不一定是正样本,因为存在标题诱惑(clickbait)的问题。
- 把视频的上传时间作为训练的输入特征,用来解释视频最开始的受欢迎程度;
- 实际预测是用户点击视频的时刻,使用加权的LR进行预测。
5. 一点思考
- 深度学习是成为未来发展的一个重大趋势
YouTube has undergone a fundamental paradigm shift towards using deep learning as a general-purpose solution for nearly all learning problems.
- 模型分层——两阶段神经网络
The system is comprised of two neural networks: one for candidate generation and one for ranking.
本质上,这里的神经网络模型是一个巨大的filter,这两个filters和用户的输入决定了应该为用户推荐哪些视频。这两个filters的输入以及处理的数据都是不一样的,越接近用户的输入,filter处理的数据量越大,特征越粗糙;越接近输出或者模型产出,filter处理的数据量越小,特征越精细。
- 观看时长(watch time)
Assigning a score to each video according to a desired objective function using a rich set of features describing the video and user. Our Goal is to predict expected watch time. Our final ranking objective is constantly being tuned based on live A/B testing results but is generally a simple function of expected watch time per impression.
影响观看时长的所有因子都会被加入到算法,算法通过A/B testing的方式提升用户更大的观看时长,用户决定观看哪些视频,决定不看哪些视频,然后将产生的数据回流到神经网络,模型将那些点击的、观看较长时长的视频保留下来,而将没有被点击的视频考虑下一步在Candidate generation阶段过滤掉,这样Youtube可以进一步提高观看时长。
-
一个尖锐的问题——为什么这些视频会被推荐? why are videos successful?
这篇文章提到ranking model用到了几百个特征,但是并没有具体描述用到那些特征,或者这些特征是如何加权的。不过从这篇文章也提到了推荐的灵魂——Training examples are generated from all YouTube watches rather than just watches on the recommendations we produce,YouTube算法的核心最终还是回归到观看时长(watch time)。